Homework 2
In this blog, I will discover my favorite movies on the IMDB website. I will use webscraping to find the movie or TV shows that share actors with my favorite movie or shows.
1. Setup
My favorite movie is Harry Potter and the Sorcerer’s Stone. Its IMDB page is at: https://www.imdb.com/title/tt0241527/

I will create a new GitHub repository. This repository will house my scraper. The following link is my repository: https://github.com/TianliangTao/Web-Scraping
2. Write my Scraper
Create a file inside the spiders directory called imdb_spider.py.
import scrapy
class ImdbSpider(scrapy.Spider):
# define an unique name for spider class
name = 'imdb_spider'
# start scraping from
start_urls = ['https://www.imdb.com/title/tt0241527/']
I will implement three parsing methods for the ImdbSpider class.
First, i will use parse(self, response). I will use this function to navigate to the Cast & Crew_ page. This method can help us to know what to do with the response object.
def parse(self, response):
'''
This method is to start on a movie page, and then navigate to the Cast page.
And call the parse_full_credits(self, response).
'''
url = response.url + "fullcredits/"
yield scrapy.Request(url, callback = self.parse_full_credits)
Second, I will use parse_full_credits(self,response). This function is to yield a scrapy.Request for the page of each actor listed on the page.
def parse_full_credits(self, response):
'''
This method is to yield a scrapy.Request for the page of each actor listed on the page.
And call the method parse_actor_page(self, response)
'''
# this command mimics the process of clicking on the headshots on this page
cast = [a.attrib["href"] for a in response.css("td.primary_photo a")]
for actor in cast:
url = "https://www.imdb.com" + actor
yield scrapy.Request(url, callback = self.parse_actor_page)
Last, I will use parse_actor_page(self, response). This function is to yield a dictionary with two key-value pairs.
def parse_actor_page(self, response):
'''
This method is to yield a dictionary with two key-value pairs.
It should yield one such dictionary for each of the movies or TV shows.
'''
for movie_or_tv in response.css("div.filmo-row"):
# extract actor's name
actor = response.css("span.itemprop::text").get()
# extract movie or tv's name
Movie_or_TV = movie_or_tv.css("div.filmo-row b a::text").get()
yield{
"actor":actor,
"Movie_or_TV":Movie_or_TV
}
In order to reduce the running time, I will use `
CLOSESPIDER_PAGECOUNT = 20 limit the crawling page to 20. And then using command scrapy crawl imdb_spider -o results.csv on the terminal. This command can help us create a .csv` file.
3. Analyze the data
In this part, I will check the data that I crawled from the IMDB. Clean and sort the date. I will sort the data with a descending way.
import pandas as pd
# read data
df = pd.read_csv("results.csv")
df_1 = df.pivot_table(index = ["Movie_or_TV"], aggfunc = 'size')
df_1 = df_1.reset_index()
df_1 = df_1.rename(columns = { 0: "number of shared actors"})
# sort number of shared actors in an ascending order
df_1 = df_1.sort_values(by=["number of shared actors"], ascending=False)
df_1 = df_1.reset_index()
df_1 = df_1.drop(["index"], axis=1)
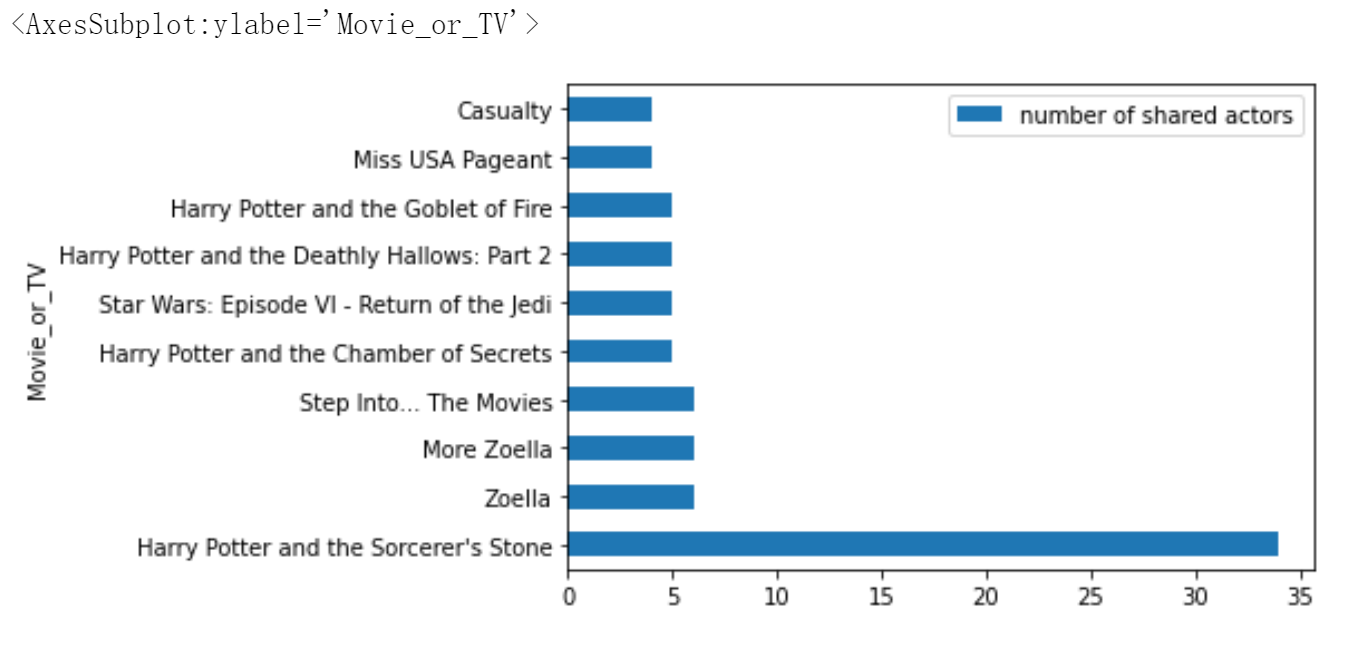
df_1.head(10)
| Movie_or_TV | number of shared actors | |
|---|---|---|
| 0 | Harry Potter and the Sorcerer's Stone | 34 |
| 1 | Zoella | 6 |
| 2 | More Zoella | 6 |
| 3 | Step Into... The Movies | 6 |
| 4 | Harry Potter and the Chamber of Secrets | 5 |
| 5 | Star Wars: Episode VI - Return of the Jedi | 5 |
| 6 | Harry Potter and the Deathly Hallows: Part 2 | 5 |
| 7 | Harry Potter and the Goblet of Fire | 5 |
| 8 | Miss USA Pageant | 4 |
| 9 | Casualty | 4 |
Final step is to visualize the data with matplotlib.
from plotly import express as px
df_2 = df_1.head(10)
df_2.plot.barh(x="Movie_or_TV",y="number of shared actors")