
Homework 3
In this assignment, I will use several new skills and concepts related to image classification in Tensorflow. And use Tensorflow to to distinguish between pictures of dogs and pictures of cats.
§1. Load Packages and Obtain Data
First setp is loading the package that we might use in this project.
import os
import tensorflow as tf
from tensorflow.keras import utils, models, layers
import matplotlib.pyplot as plt
import numpy as np
Then, access the data that contains labeled images of cats and dogs.
# location of data
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
# download the data and extract it
path_to_zip = utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
# construct paths
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
# parameters for datasets
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
# construct train and validation datasets
train_dataset = utils.image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
validation_dataset = utils.image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
# construct the test dataset by taking every 5th observation out of the validation dataset
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
Downloading data from https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
68608000/68606236 [==============================] - 1s 0us/step
68616192/68606236 [==============================] - 1s 0us/step
Found 2000 files belonging to 2 classes.
Found 1000 files belonging to 2 classes.
Using the tf.dataAPI to build highly performant TensorFlow input pipelines.
AUTOTUNE = tf.data.AUTOTUNE
train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)
validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)
test_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE)
Working with Datasets
In this step, we will retrieve one batch from the training data. And define a function to create a two-row visualization.
def show_images():
image_batch, label_batch = next(iter(train_dataset))
class_names = ["cat", "dog"]
plt.figure(figsize=(10, 10))
j = 0
k = 0
for i in range(32):
if class_names[label_batch[i]] == "cat" and j < 3:
ax = plt.subplot(2, 3, j + 1)
plt.imshow(image_batch[i].numpy().astype("uint8"))
label = label_batch[i]
plt.title(class_names[label])
plt.axis("off")
j = j +1
elif class_names[label_batch[i]] == "dog" and k < 3:
ax = plt.subplot(2, 3, k + 4)
plt.imshow(image_batch[i].numpy().astype("uint8"))
label = label_batch[i]
plt.title(class_names[label])
plt.axis("off")
k = k + 1
show_images()
Then we get 6 pictures. Three random pictures of cats in the first row. Three random pictures of dogs in the second row.

Check Label Frequencies
Create an iterator called labels.
labels_iterator= train_dataset.unbatch().map(lambda image, label: label).as_numpy_iterator()
Compute the number of images in the training data with label 0 (corresponding to "cat") and label 1 (corresponding to "dog").
j = 0
k = 0
for i in labels_iterator:
if i==1:
j+=1
else:
k+=1
print("The number of images in the training data with dogs: ", j)
print("The number of images in the training data with cats: ", k)
The number of images in the training data with dogs: 1000
The number of images in the training data with cats: 1000
§2. First Model
Use multiple layers to construct a models.Sequential model. And train a model on a Dataset.
model1 = models.Sequential([layers.Conv2D(64, (3,3), activation='relu', input_shape=(160, 160, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3,3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dropout(0.1),
layers.Dense(128, activation="relu"),
layers.Dense(64, activation="relu"),
layers.Dropout(0.1),
layers.Dense(10, activation="relu")])
model1.compile(optimizer='adam',
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics = ['accuracy'])
history = model1.fit(train_dataset,
epochs=20,
validation_data=validation_dataset)
Epoch 1/20
63/63 [==============================] - 5s 72ms/step - loss: 27.8931 - accuracy: 0.5240 - val_loss: 0.6912 - val_accuracy: 0.5483
Epoch 2/20
63/63 [==============================] - 5s 69ms/step - loss: 0.6841 - accuracy: 0.5895 - val_loss: 0.6838 - val_accuracy: 0.6002
Epoch 3/20
63/63 [==============================] - 5s 82ms/step - loss: 0.6502 - accuracy: 0.6625 - val_loss: 1.0635 - val_accuracy: 0.5248
Epoch 4/20
63/63 [==============================] - 5s 71ms/step - loss: 0.6082 - accuracy: 0.6975 - val_loss: 0.7426 - val_accuracy: 0.6027
Epoch 5/20
63/63 [==============================] - 5s 70ms/step - loss: 0.4593 - accuracy: 0.7865 - val_loss: 0.9274 - val_accuracy: 0.5903
Epoch 6/20
63/63 [==============================] - 5s 70ms/step - loss: 0.3402 - accuracy: 0.8530 - val_loss: 1.4487 - val_accuracy: 0.5780
Epoch 7/20
63/63 [==============================] - 5s 70ms/step - loss: 0.2733 - accuracy: 0.8865 - val_loss: 1.2185 - val_accuracy: 0.6015
Epoch 8/20
63/63 [==============================] - 5s 70ms/step - loss: 0.2110 - accuracy: 0.9160 - val_loss: 1.9098 - val_accuracy: 0.5941
Epoch 9/20
63/63 [==============================] - 5s 69ms/step - loss: 0.1699 - accuracy: 0.9370 - val_loss: 2.0799 - val_accuracy: 0.5903
Epoch 10/20
63/63 [==============================] - 5s 70ms/step - loss: 0.1962 - accuracy: 0.9225 - val_loss: 1.7408 - val_accuracy: 0.5767
Epoch 11/20
63/63 [==============================] - 5s 70ms/step - loss: 0.1171 - accuracy: 0.9555 - val_loss: 1.6767 - val_accuracy: 0.5743
Epoch 12/20
63/63 [==============================] - 5s 70ms/step - loss: 0.1036 - accuracy: 0.9705 - val_loss: 1.6483 - val_accuracy: 0.5668
Epoch 13/20
63/63 [==============================] - 5s 69ms/step - loss: 0.1738 - accuracy: 0.9315 - val_loss: 2.4328 - val_accuracy: 0.5866
Epoch 14/20
63/63 [==============================] - 5s 70ms/step - loss: 0.1492 - accuracy: 0.9645 - val_loss: 1.4749 - val_accuracy: 0.5854
Epoch 15/20
63/63 [==============================] - 5s 69ms/step - loss: 0.0660 - accuracy: 0.9775 - val_loss: 2.0641 - val_accuracy: 0.5804
Epoch 16/20
63/63 [==============================] - 5s 70ms/step - loss: 0.0660 - accuracy: 0.9745 - val_loss: 3.1742 - val_accuracy: 0.5842
Epoch 17/20
63/63 [==============================] - 5s 69ms/step - loss: 0.0388 - accuracy: 0.9840 - val_loss: 3.2158 - val_accuracy: 0.5767
Epoch 18/20
63/63 [==============================] - 5s 70ms/step - loss: 0.0327 - accuracy: 0.9905 - val_loss: 3.0004 - val_accuracy: 0.5928
Epoch 19/20
63/63 [==============================] - 5s 70ms/step - loss: 0.0269 - accuracy: 0.9915 - val_loss: 3.1772 - val_accuracy: 0.5978
Epoch 20/20
63/63 [==============================] - 5s 70ms/step - loss: 0.0462 - accuracy: 0.9895 - val_loss: 3.2968 - val_accuracy: 0.6077
Visualize the training accuracy and validation accuracy.
plt.plot(history.history["accuracy"], label = "training")
plt.plot(history.history["val_accuracy"], label = "validation")
plt.gca().set(xlabel = "epoch", ylabel = "accuracy")
plt.legend()
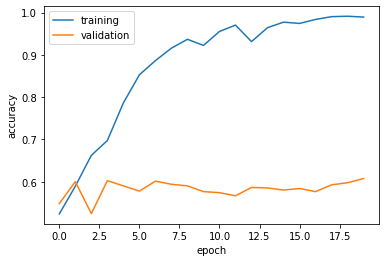
According to the training history, the validation accuracy of model1 is between 52.48% - 60.77% during training. Compare to the baseline, my model improved 8% of accuracy. Compare to the training accuracy, model1 is overfitting because the training accuracy is much higher than the validation accuracy.
§3. Model with Data Augmentation
Using RandomFlip() layer and RandomRotation() layer to flip and rotate a picture.
def images():
image_aug1 = tf.keras.Sequential([layers.experimental.preprocessing.RandomFlip("horizontal")])
image_aug2 = tf.keras.Sequential(layers.experimental.preprocessing.RandomRotation(0.3))
image_batch, label_batch = next(iter(train_dataset))
plt.figure(figsize=(15, 15))
for i in range(8):
if i == 0 or i == 4:
ax = plt.subplot(2,4,i+1)
plt.imshow(image_batch[0]/255)
plt.title("Origin")
plt.axis('off')
elif 0 < i < 4:
aug_image = image_aug1(tf.expand_dims(image_batch[0], 0))
ax = plt.subplot(2,4,i+1)
plt.imshow(aug_image[0]/255)
plt.title("RandomFlip")
plt.axis('off')
else:
aug_image = image_aug2(tf.expand_dims(image_batch[0], 0))
ax = plt.subplot(2,4,i+1)
plt.imshow(aug_image[0]/255)
plt.title("RandomFlip")
plt.axis('off')
images()
 Use multiple layers to construct a
Use multiple layers to construct a tf.keras.models.Sequential model. And train a model on a Dataset.
model2 = tf.keras.Sequential([layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.3),
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(32, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dropout(0.2),
layers.Dense(64, activation='relu'),
layers.Dense(2)])
model2.compile(optimizer='adam',
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics = ['accuracy'])
history = model2.fit(train_dataset,
epochs=20,
validation_data=validation_dataset)
Epoch 1/20
63/63 [==============================] - 8s 71ms/step - loss: 6.1335 - accuracy: 0.5345 - val_loss: 0.6942 - val_accuracy: 0.5866
Epoch 2/20
63/63 [==============================] - 5s 68ms/step - loss: 0.6943 - accuracy: 0.5685 - val_loss: 0.6660 - val_accuracy: 0.5866
Epoch 3/20
63/63 [==============================] - 5s 68ms/step - loss: 0.6713 - accuracy: 0.5870 - val_loss: 0.6698 - val_accuracy: 0.5965
Epoch 4/20
63/63 [==============================] - 5s 68ms/step - loss: 0.6636 - accuracy: 0.6070 - val_loss: 0.6554 - val_accuracy: 0.6200
Epoch 5/20
63/63 [==============================] - 5s 67ms/step - loss: 0.6676 - accuracy: 0.6005 - val_loss: 0.6678 - val_accuracy: 0.5619
Epoch 6/20
63/63 [==============================] - 4s 66ms/step - loss: 0.6549 - accuracy: 0.6120 - val_loss: 0.6706 - val_accuracy: 0.6275
Epoch 7/20
63/63 [==============================] - 4s 66ms/step - loss: 0.6718 - accuracy: 0.6085 - val_loss: 0.6539 - val_accuracy: 0.6337
Epoch 8/20
63/63 [==============================] - 4s 66ms/step - loss: 0.6550 - accuracy: 0.6000 - val_loss: 0.6492 - val_accuracy: 0.6361
Epoch 9/20
63/63 [==============================] - 4s 66ms/step - loss: 0.6473 - accuracy: 0.6160 - val_loss: 0.6445 - val_accuracy: 0.6188
Epoch 10/20
63/63 [==============================] - 4s 66ms/step - loss: 0.6291 - accuracy: 0.6570 - val_loss: 0.6179 - val_accuracy: 0.6597
Epoch 11/20
63/63 [==============================] - 5s 76ms/step - loss: 0.6372 - accuracy: 0.6350 - val_loss: 0.6371 - val_accuracy: 0.6361
Epoch 12/20
63/63 [==============================] - 4s 66ms/step - loss: 0.6298 - accuracy: 0.6465 - val_loss: 0.6319 - val_accuracy: 0.6448
Epoch 13/20
63/63 [==============================] - 4s 67ms/step - loss: 0.6307 - accuracy: 0.6310 - val_loss: 0.6506 - val_accuracy: 0.6807
Epoch 14/20
63/63 [==============================] - 5s 68ms/step - loss: 0.6476 - accuracy: 0.6375 - val_loss: 0.6466 - val_accuracy: 0.6188
Epoch 15/20
63/63 [==============================] - 4s 66ms/step - loss: 0.6261 - accuracy: 0.6525 - val_loss: 0.5964 - val_accuracy: 0.6658
Epoch 16/20
63/63 [==============================] - 4s 67ms/step - loss: 0.6143 - accuracy: 0.6570 - val_loss: 0.6001 - val_accuracy: 0.6819
Epoch 17/20
63/63 [==============================] - 4s 65ms/step - loss: 0.6176 - accuracy: 0.6675 - val_loss: 0.6257 - val_accuracy: 0.6522
Epoch 18/20
63/63 [==============================] - 4s 66ms/step - loss: 0.6050 - accuracy: 0.6695 - val_loss: 0.5928 - val_accuracy: 0.6819
Epoch 19/20
63/63 [==============================] - 5s 67ms/step - loss: 0.6095 - accuracy: 0.6675 - val_loss: 0.6211 - val_accuracy: 0.6287
Epoch 20/20
63/63 [==============================] - 4s 67ms/step - loss: 0.6019 - accuracy: 0.6790 - val_loss: 0.6133 - val_accuracy: 0.6658
Visualize the training accuracy and validation accuracy.
plt.plot(history.history["accuracy"], label = "training")
plt.plot(history.history["val_accuracy"], label = "validation")
plt.gca().set(xlabel = "epoch", ylabel = "accuracy")
plt.legend()
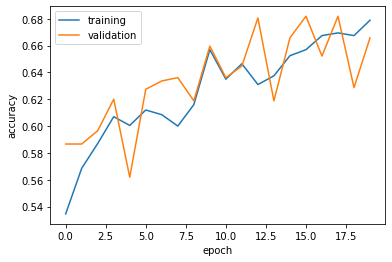
According to the training history, the validation accuracy of model2 is between 56.19% - 68.19% during training. Compare to the model1, the accuracy of model2is better. Compare to the training accuracy, model2 is not overfitting because the validation accuracy are close to the training accuracy.
§4. Data Preprocessing
Create a preprocessing layer called preprocessor which we can slot into our model pipeline.
i = tf.keras.Input(shape=(160, 160, 3))
x = tf.keras.applications.mobilenet_v2.preprocess_input(i)
preprocessor = tf.keras.Model(inputs = [i], outputs = [x])
Use multiple layers to construct a tf.keras.models.Sequential model. And train a model on a Dataset.
model3 = tf.keras.Sequential([preprocessor,
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.3),
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(32, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dropout(0.2),
layers.Dense(64, activation='relu'),
layers.Dense(2)])
model3.compile(optimizer='adam',
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics = ['accuracy'])
history = model3.fit(train_dataset,
epochs=20,
validation_data=validation_dataset)
Epoch 1/20
63/63 [==============================] - 6s 70ms/step - loss: 0.7171 - accuracy: 0.5080 - val_loss: 0.6847 - val_accuracy: 0.5173
Epoch 2/20
63/63 [==============================] - 5s 73ms/step - loss: 0.6725 - accuracy: 0.5685 - val_loss: 0.6483 - val_accuracy: 0.6498
Epoch 3/20
63/63 [==============================] - 5s 69ms/step - loss: 0.6434 - accuracy: 0.6200 - val_loss: 0.6265 - val_accuracy: 0.6559
Epoch 4/20
63/63 [==============================] - 5s 68ms/step - loss: 0.6304 - accuracy: 0.6410 - val_loss: 0.6199 - val_accuracy: 0.6720
Epoch 5/20
63/63 [==============================] - 5s 70ms/step - loss: 0.6083 - accuracy: 0.6715 - val_loss: 0.6093 - val_accuracy: 0.6498
Epoch 6/20
63/63 [==============================] - 5s 69ms/step - loss: 0.5987 - accuracy: 0.6840 - val_loss: 0.5906 - val_accuracy: 0.6980
Epoch 7/20
63/63 [==============================] - 5s 71ms/step - loss: 0.5904 - accuracy: 0.6820 - val_loss: 0.5817 - val_accuracy: 0.7005
Epoch 8/20
63/63 [==============================] - 5s 69ms/step - loss: 0.5700 - accuracy: 0.7025 - val_loss: 0.5685 - val_accuracy: 0.7067
Epoch 9/20
63/63 [==============================] - 5s 69ms/step - loss: 0.5684 - accuracy: 0.7025 - val_loss: 0.5871 - val_accuracy: 0.7030
Epoch 10/20
63/63 [==============================] - 9s 127ms/step - loss: 0.5631 - accuracy: 0.7045 - val_loss: 0.5640 - val_accuracy: 0.7191
Epoch 11/20
63/63 [==============================] - 5s 71ms/step - loss: 0.5519 - accuracy: 0.7120 - val_loss: 0.5467 - val_accuracy: 0.7240
Epoch 12/20
63/63 [==============================] - 5s 76ms/step - loss: 0.5476 - accuracy: 0.7150 - val_loss: 0.5720 - val_accuracy: 0.7191
Epoch 13/20
63/63 [==============================] - 5s 71ms/step - loss: 0.5474 - accuracy: 0.7050 - val_loss: 0.5853 - val_accuracy: 0.6993
Epoch 14/20
63/63 [==============================] - 5s 69ms/step - loss: 0.5392 - accuracy: 0.7230 - val_loss: 0.6104 - val_accuracy: 0.6856
Epoch 15/20
63/63 [==============================] - 5s 68ms/step - loss: 0.5303 - accuracy: 0.7375 - val_loss: 0.6064 - val_accuracy: 0.6795
Epoch 16/20
63/63 [==============================] - 5s 69ms/step - loss: 0.5326 - accuracy: 0.7260 - val_loss: 0.5692 - val_accuracy: 0.7116
Epoch 17/20
63/63 [==============================] - 5s 71ms/step - loss: 0.5296 - accuracy: 0.7290 - val_loss: 0.5488 - val_accuracy: 0.7104
Epoch 18/20
63/63 [==============================] - 5s 71ms/step - loss: 0.5252 - accuracy: 0.7355 - val_loss: 0.5672 - val_accuracy: 0.7104
Epoch 19/20
63/63 [==============================] - 5s 70ms/step - loss: 0.5216 - accuracy: 0.7315 - val_loss: 0.5431 - val_accuracy: 0.7413
Epoch 20/20
63/63 [==============================] - 5s 71ms/step - loss: 0.5113 - accuracy: 0.7535 - val_loss: 0.5812 - val_accuracy: 0.7005
Visualize the training accuracy and validation accuracy.
plt.plot(history.history["accuracy"], label = "training")
plt.plot(history.history["val_accuracy"], label = "validation")
plt.gca().set(xlabel = "epoch", ylabel = "accuracy")
plt.legend()
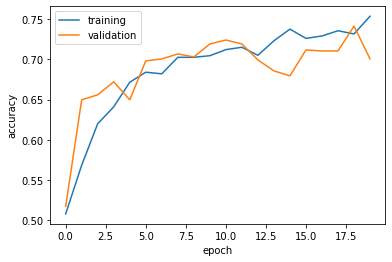
According to the training history, the validation accuracy of model3 is between 51.73% - 74.13% during training. Compare to the model1, the accuracy of model3is better. Compare to the training accuracy, model3 is not overfitting because the validation accuracy are close to the training accuracy.
§5. Transfer Learning
Download MobileNetV2 and configure it as a layer .
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
base_model.trainable = False
i = tf.keras.Input(shape=IMG_SHAPE)
x = base_model(i, training = False)
base_model_layer = tf.keras.Model(inputs = [i], outputs = [x])
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_160_no_top.h5
9412608/9406464 [==============================] - 0s 0us/step
9420800/9406464 [==============================] - 0s 0us/step
Use multiple layers to construct a tf.keras.models.Sequential model. And train a model on a Dataset.
model4 = tf.keras.Sequential([preprocessor,
layers.RandomFlip('horizontal'),
layers.RandomRotation(0.2),
base_model_layer,
layers.Flatten(),
layers.Dropout(0.2),
layers.Dense(2)])
Use model.summary() check the model.
model4.summary()
Model: "sequential_20"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
model (Functional) (None, 160, 160, 3) 0
random_flip_18 (RandomFlip) (None, 160, 160, 3) 0
random_rotation_18 (RandomRotation) (None, 160, 160, 3) 0
model_1 (Functional) (None, 5, 5, 1280) 2257984
flatten_15 (Flatten) (None, 32000) 0
dropout_12 (Dropout) (None, 32000) 0
dense_29 (Dense) (None, 2) 64002
=================================================================
Total params: 2,321,986
Trainable params: 64,002
Non-trainable params: 2,257,984
_________________________________________________________________
Check the training history of model4.
model4.compile(optimizer='adam',
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics = ['accuracy'])
history = model4.fit(train_dataset,
epochs=20,
validation_data=validation_dataset)
Epoch 1/20
63/63 [==============================] - 11s 91ms/step - loss: 0.7733 - accuracy: 0.8990 - val_loss: 0.1656 - val_accuracy: 0.9752
Epoch 2/20
63/63 [==============================] - 5s 76ms/step - loss: 0.4988 - accuracy: 0.9350 - val_loss: 0.1166 - val_accuracy: 0.9851
Epoch 3/20
63/63 [==============================] - 5s 75ms/step - loss: 0.4411 - accuracy: 0.9490 - val_loss: 0.1164 - val_accuracy: 0.9839
Epoch 4/20
63/63 [==============================] - 5s 75ms/step - loss: 0.3398 - accuracy: 0.9545 - val_loss: 0.1111 - val_accuracy: 0.9839
Epoch 5/20
63/63 [==============================] - 5s 75ms/step - loss: 0.3692 - accuracy: 0.9600 - val_loss: 0.1315 - val_accuracy: 0.9851
Epoch 6/20
63/63 [==============================] - 5s 75ms/step - loss: 0.3317 - accuracy: 0.9570 - val_loss: 0.1347 - val_accuracy: 0.9827
Epoch 7/20
63/63 [==============================] - 5s 75ms/step - loss: 0.3374 - accuracy: 0.9605 - val_loss: 0.2590 - val_accuracy: 0.9814
Epoch 8/20
63/63 [==============================] - 5s 76ms/step - loss: 0.4316 - accuracy: 0.9550 - val_loss: 0.6630 - val_accuracy: 0.9517
Epoch 9/20
63/63 [==============================] - 5s 75ms/step - loss: 0.3889 - accuracy: 0.9625 - val_loss: 0.2272 - val_accuracy: 0.9790
Epoch 10/20
63/63 [==============================] - 5s 76ms/step - loss: 0.3488 - accuracy: 0.9660 - val_loss: 0.1750 - val_accuracy: 0.9814
Epoch 11/20
63/63 [==============================] - 5s 75ms/step - loss: 0.2798 - accuracy: 0.9715 - val_loss: 0.2123 - val_accuracy: 0.9827
Epoch 12/20
63/63 [==============================] - 5s 76ms/step - loss: 0.2839 - accuracy: 0.9690 - val_loss: 0.2484 - val_accuracy: 0.9802
Epoch 13/20
63/63 [==============================] - 5s 75ms/step - loss: 0.2790 - accuracy: 0.9715 - val_loss: 0.3385 - val_accuracy: 0.9777
Epoch 14/20
63/63 [==============================] - 5s 75ms/step - loss: 0.2898 - accuracy: 0.9790 - val_loss: 0.2934 - val_accuracy: 0.9839
Epoch 15/20
63/63 [==============================] - 5s 75ms/step - loss: 0.2816 - accuracy: 0.9780 - val_loss: 0.2623 - val_accuracy: 0.9802
Epoch 16/20
63/63 [==============================] - 6s 97ms/step - loss: 0.1901 - accuracy: 0.9730 - val_loss: 0.2810 - val_accuracy: 0.9777
Epoch 17/20
63/63 [==============================] - 5s 75ms/step - loss: 0.1530 - accuracy: 0.9840 - val_loss: 0.1927 - val_accuracy: 0.9839
Epoch 18/20
63/63 [==============================] - 5s 75ms/step - loss: 0.3235 - accuracy: 0.9715 - val_loss: 0.3830 - val_accuracy: 0.9802
Epoch 19/20
63/63 [==============================] - 5s 76ms/step - loss: 0.2573 - accuracy: 0.9800 - val_loss: 0.2940 - val_accuracy: 0.9851
Epoch 20/20
63/63 [==============================] - 5s 76ms/step - loss: 0.2585 - accuracy: 0.9795 - val_loss: 0.2882 - val_accuracy: 0.9827
Visualize the training accuracy and validation accuracy.
plt.plot(history.history["accuracy"], label = "training")
plt.plot(history.history["val_accuracy"], label = "validation")
plt.gca().set(xlabel = "epoch", ylabel = "accuracy")
plt.legend()
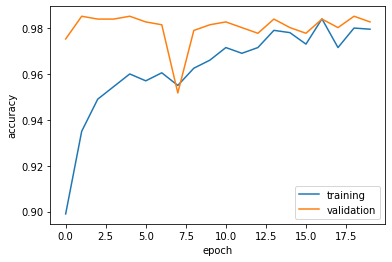 According to the training history, the validation accuracy of
According to the training history, the validation accuracy of model4 is between 95.17% - 98.51% during training. Compare to the model1, the accuracy of model4is better. Compare to the training accuracy, model4 is not overfitting because the validation accuracy are close to the training accuracy.
§6. Score on Test Data
Evaluate the accuracy of models on the unseen test_dataset.
model1.evaluate(test_dataset)
model2.evaluate(test_dataset)
model3.evaluate(test_dataset)
model4.evaluate(test_dataset)
6/6 [==============================] - 1s 49ms/step - loss: 2.5404 - accuracy: 0.5781
6/6 [==============================] - 1s 49ms/step - loss: 0.6580 - accuracy: 0.5885
6/6 [==============================] - 1s 47ms/step - loss: 0.5422 - accuracy: 0.7292
6/6 [==============================] - 1s 54ms/step - loss: 0.1924 - accuracy: 0.9792
[0.192388653755188, 0.9791666865348816]
According to result, we can find that model4 is the most performant model on the unseen test_dataset. The accuracy of test data is 97.92% in model4.