
Homework 4
In this blog, I will develop and assess a fake news classifer using Tensorflow.
1. Acquire Training Data
import pandas as pd
import numpy as np
train_url = "https://github.com/PhilChodrow/PIC16b/blob/master/datasets/fake_news_train.csv?raw=true"
df = pd.read_csv(train_url)
Using df.head() check the data that get from train_url.
df.head()
| Unnamed: 0 | title | text | fake | |
|---|---|---|---|---|
| 0 | 17366 | Merkel: Strong result for Austria's FPO 'big c... | German Chancellor Angela Merkel said on Monday... | 0 |
| 1 | 5634 | Trump says Pence will lead voter fraud panel | WEST PALM BEACH, Fla.President Donald Trump sa... | 0 |
| 2 | 17487 | JUST IN: SUSPECTED LEAKER and Close Confidant... | On December 5, 2017, Circa s Sara Carter warne... | 1 |
| 3 | 12217 | Thyssenkrupp has offered help to Argentina ove... | Germany s Thyssenkrupp, has offered assistance... | 0 |
| 4 | 5535 | Trump say appeals court decision on travel ban... | President Donald Trump on Thursday called the ... | 0 |
2. Make a Dataset
Write a function make_dataset. First,And remove stopwords from the text and title. Then, using construct and use tf.data.Dataset with multiple inputs. Finally, batch hte dataset and return the dataset.
import tensorflow as tf
from nltk.corpus import stopwords
stop = stopwords.words('english')
def make_dataset(df):
df["title"] = df["title"].apply(lambda x: " ".join([word for word in x.split() if word not in (stop)]))
df["text"] = df["text"].apply(lambda x: " ".join([word for word in x.split() if word not in (stop)]))
dataset = tf.data.Dataset.from_tensor_slices(
(
{
"title":df[["title"]],
"text":df[["text"]]
},
{
"fake":df[["fake"]]
}
)
)
data = dataset.shuffle(buffer_size = len(dataset))
data = data.batch(100)
return data
dataset = make_dataset(df)
Validation Data
Split the dataset, 80% for training, 20% for validation.
# 80% train, 20% validation
train_size = int(0.8*len(dataset))
val_size = int(0.2*len(dataset))
train = dataset.take(train_size) # data[:train_size]
val = dataset.skip(train_size).take(val_size) # data[train_size : train_size + val_size]
len(train), len(val)
(180, 45)
Base Rate
Determine the base rate for data set by examining the labels on the training set.
fake_news = np.concatenate([y.get("fake") for x, y in train], axis = 0)
sum(fake_news)/len(fake_news)
array([0.52372222])
According to the base rate, we can find that about 52.4% of the news in the training dataset is fake.
TextVectorization
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
import re
import string
#preparing a text vectorization layer for tf model
size_vocabulary = 2000
def standardization(input_data):
lowercase = tf.strings.lower(input_data)
no_punctuation = tf.strings.regex_replace(lowercase,
'[%s]' % re.escape(string.punctuation),'')
return no_punctuation
title_vectorize_layer = TextVectorization(
standardize=standardization,
max_tokens=size_vocabulary, # only consider this many words
output_mode='int',
output_sequence_length=500)
title_vectorize_layer.adapt(train.map(lambda x, y: x["title"]))
3. Create Models
To determine which model is the most effective for detecting fake news.
model 1
Using the article title as an input.
from tensorflow import keras
from tensorflow.keras import layers,losses, utils, Input
title_input = keras.Input(
shape=(1,),
name = "title", # same name as the dictionary key in the dataset
dtype = "string"
)
title_features = title_vectorize_layer(title_input) # apply this "function TextVectorization layer" to lyrics_input
title_features = layers.Embedding(size_vocabulary, 3, name="embedding_1")(title_features)
title_features = layers.Dropout(0.2)(title_features)
title_features = layers.GlobalAveragePooling1D()(title_features)
title_features = layers.Dropout(0.2)(title_features)
title_features = layers.Dense(32, activation='relu')(title_features)
main = layers.Dense(32, activation='relu')(title_features)
output = layers.Dense(1, name="fake")(main)
model_1 = keras.Model(
inputs = title_input,
outputs = output
)
model_1.compile(optimizer = "adam",
loss = losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model_1.fit(train,
validation_data=val,
epochs = 20)
Epoch 1/20
180/180 [==============================] - 1s 6ms/step - loss: 0.0516 - accuracy: 0.9788 - val_loss: 0.0292 - val_accuracy: 0.9883
Epoch 2/20
180/180 [==============================] - 1s 5ms/step - loss: 0.0508 - accuracy: 0.9798 - val_loss: 0.0352 - val_accuracy: 0.9849
Epoch 3/20
180/180 [==============================] - 1s 5ms/step - loss: 0.0528 - accuracy: 0.9791 - val_loss: 0.0264 - val_accuracy: 0.9897
Epoch 4/20
180/180 [==============================] - 1s 5ms/step - loss: 0.0489 - accuracy: 0.9799 - val_loss: 0.0426 - val_accuracy: 0.9890
Epoch 5/20
180/180 [==============================] - 1s 5ms/step - loss: 0.0508 - accuracy: 0.9804 - val_loss: 0.0290 - val_accuracy: 0.9894
Epoch 6/20
180/180 [==============================] - 1s 5ms/step - loss: 0.0481 - accuracy: 0.9798 - val_loss: 0.0238 - val_accuracy: 0.9901
Epoch 7/20
180/180 [==============================] - 1s 5ms/step - loss: 0.0475 - accuracy: 0.9820 - val_loss: 0.0294 - val_accuracy: 0.9899
Epoch 8/20
180/180 [==============================] - 1s 5ms/step - loss: 0.0445 - accuracy: 0.9828 - val_loss: 0.0308 - val_accuracy: 0.9903
Epoch 9/20
180/180 [==============================] - 1s 5ms/step - loss: 0.0480 - accuracy: 0.9807 - val_loss: 0.0241 - val_accuracy: 0.9944
Epoch 10/20
180/180 [==============================] - 1s 5ms/step - loss: 0.0432 - accuracy: 0.9824 - val_loss: 0.0199 - val_accuracy: 0.9919
Epoch 11/20
180/180 [==============================] - 1s 5ms/step - loss: 0.0503 - accuracy: 0.9811 - val_loss: 0.0256 - val_accuracy: 0.9908
Epoch 12/20
180/180 [==============================] - 1s 5ms/step - loss: 0.0437 - accuracy: 0.9818 - val_loss: 0.0210 - val_accuracy: 0.9906
Epoch 13/20
180/180 [==============================] - 1s 5ms/step - loss: 0.0476 - accuracy: 0.9800 - val_loss: 0.0222 - val_accuracy: 0.9906
Epoch 14/20
180/180 [==============================] - 1s 5ms/step - loss: 0.0472 - accuracy: 0.9816 - val_loss: 0.0283 - val_accuracy: 0.9892
Epoch 15/20
180/180 [==============================] - 1s 5ms/step - loss: 0.0460 - accuracy: 0.9817 - val_loss: 0.0427 - val_accuracy: 0.9892
Epoch 16/20
180/180 [==============================] - 1s 5ms/step - loss: 0.0429 - accuracy: 0.9826 - val_loss: 0.0343 - val_accuracy: 0.9894
Epoch 17/20
180/180 [==============================] - 1s 5ms/step - loss: 0.0425 - accuracy: 0.9829 - val_loss: 0.0325 - val_accuracy: 0.9906
Epoch 18/20
180/180 [==============================] - 1s 5ms/step - loss: 0.0433 - accuracy: 0.9820 - val_loss: 0.0281 - val_accuracy: 0.9924
Epoch 19/20
180/180 [==============================] - 1s 5ms/step - loss: 0.0455 - accuracy: 0.9819 - val_loss: 0.0265 - val_accuracy: 0.9917
Epoch 20/20
180/180 [==============================] - 1s 5ms/step - loss: 0.0417 - accuracy: 0.9839 - val_loss: 0.0193 - val_accuracy: 0.9917
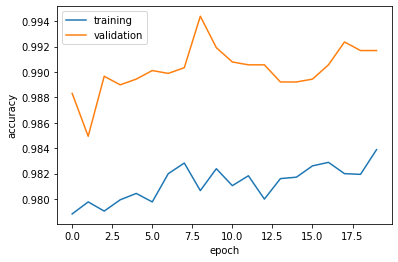
Then, viualize the training history.
from matplotlib import pyplot as plt
plt.plot(history.history["accuracy"], label = "training")
plt.plot(history.history["val_accuracy"], label = "validation")
plt.gca().set(xlabel = "epoch", ylabel = "accuracy")
plt.legend()
model 2
Using the artial text as an input.
text_input = keras.Input(
shape=(1,),
name = "text", # same name as the dictionary key in the dataset
dtype = "string"
)
text_features = title_vectorize_layer(text_input) # apply this "function TextVectorization layer" to text_input
text_features = layers.Embedding(size_vocabulary, 3, name="embedding_2")(text_features)
text_features = layers.Dropout(0.2)(text_features)
text_features = layers.GlobalAveragePooling1D()(text_features)
text_features = layers.Dropout(0.2)(text_features)
text_features = layers.Dense(32, activation='relu')(text_features)
main = layers.Dense(32, activation='relu')(text_features)
output = layers.Dense(1, name="fake")(main)
model_2 = keras.Model(
inputs = text_input,
outputs = output
)
model_2.compile(optimizer = "adam",
loss = losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model_2.fit(train,
validation_data=val,
epochs = 20)
Epoch 1/20
180/180 [==============================] - 2s 13ms/step - loss: 0.6427 - accuracy: 0.5244 - val_loss: 0.4513 - val_accuracy: 0.8033
Epoch 2/20
180/180 [==============================] - 2s 12ms/step - loss: 0.2765 - accuracy: 0.8847 - val_loss: 0.1837 - val_accuracy: 0.9337
Epoch 3/20
180/180 [==============================] - 2s 12ms/step - loss: 0.1632 - accuracy: 0.9397 - val_loss: 0.1223 - val_accuracy: 0.9476
Epoch 4/20
180/180 [==============================] - 2s 13ms/step - loss: 0.1322 - accuracy: 0.9566 - val_loss: 0.1067 - val_accuracy: 0.9546
Epoch 5/20
180/180 [==============================] - 2s 13ms/step - loss: 0.1202 - accuracy: 0.9599 - val_loss: 0.1017 - val_accuracy: 0.9539
Epoch 6/20
180/180 [==============================] - 2s 13ms/step - loss: 0.1053 - accuracy: 0.9629 - val_loss: 0.1006 - val_accuracy: 0.9748
Epoch 7/20
180/180 [==============================] - 2s 12ms/step - loss: 0.0979 - accuracy: 0.9664 - val_loss: 0.0840 - val_accuracy: 0.9728
Epoch 8/20
180/180 [==============================] - 2s 12ms/step - loss: 0.0911 - accuracy: 0.9707 - val_loss: 0.0633 - val_accuracy: 0.9802
Epoch 9/20
180/180 [==============================] - 2s 13ms/step - loss: 0.0842 - accuracy: 0.9732 - val_loss: 0.0535 - val_accuracy: 0.9874
Epoch 10/20
180/180 [==============================] - 2s 13ms/step - loss: 0.0789 - accuracy: 0.9717 - val_loss: 0.0571 - val_accuracy: 0.9856
Epoch 11/20
180/180 [==============================] - 2s 13ms/step - loss: 0.0759 - accuracy: 0.9750 - val_loss: 0.0467 - val_accuracy: 0.9888
Epoch 12/20
180/180 [==============================] - 2s 13ms/step - loss: 0.0716 - accuracy: 0.9762 - val_loss: 0.0523 - val_accuracy: 0.9854
Epoch 13/20
180/180 [==============================] - 2s 13ms/step - loss: 0.0693 - accuracy: 0.9751 - val_loss: 0.0511 - val_accuracy: 0.9874
Epoch 14/20
180/180 [==============================] - 2s 13ms/step - loss: 0.0677 - accuracy: 0.9764 - val_loss: 0.0432 - val_accuracy: 0.9915
Epoch 15/20
180/180 [==============================] - 2s 13ms/step - loss: 0.0624 - accuracy: 0.9776 - val_loss: 0.0395 - val_accuracy: 0.9897
Epoch 16/20
180/180 [==============================] - 2s 13ms/step - loss: 0.0626 - accuracy: 0.9789 - val_loss: 0.0417 - val_accuracy: 0.9903
Epoch 17/20
180/180 [==============================] - 2s 13ms/step - loss: 0.0603 - accuracy: 0.9802 - val_loss: 0.0366 - val_accuracy: 0.9894
Epoch 18/20
180/180 [==============================] - 2s 13ms/step - loss: 0.0604 - accuracy: 0.9794 - val_loss: 0.0358 - val_accuracy: 0.9921
Epoch 19/20
180/180 [==============================] - 2s 13ms/step - loss: 0.0555 - accuracy: 0.9810 - val_loss: 0.0411 - val_accuracy: 0.9906
Epoch 20/20
180/180 [==============================] - 2s 13ms/step - loss: 0.0551 - accuracy: 0.9824 - val_loss: 0.0376 - val_accuracy: 0.9917
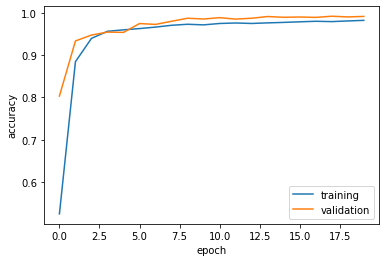
Then, viualize the training history.
plt.plot(history.history["accuracy"], label = "training")
plt.plot(history.history["val_accuracy"], label = "validation")
plt.gca().set(xlabel = "epoch", ylabel = "accuracy")
plt.legend()
model 3
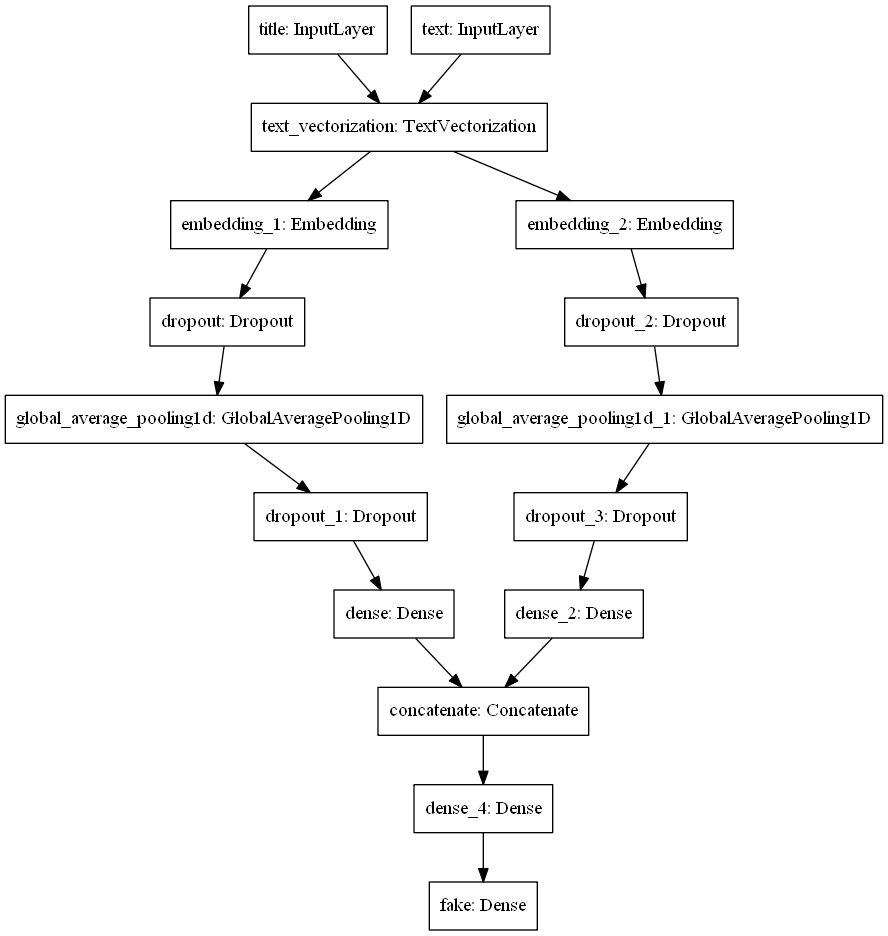
Using both the article title and the article text as input. And embedding layer for both the article title and text inputs.
main = layers.concatenate([title_features, text_features], axis = 1)
main = layers.Dense(32, activation='relu')(main)
output = layers.Dense(1, name="fake")(main)
model_3 = keras.Model(
inputs = [title_input, text_input],
outputs = output
)
Visualize the model.
utils.plot_model(model_3)
model_3.compile(optimizer = "adam",
loss = losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model_3.fit(train,
validation_data=val,
epochs = 20)
Epoch 1/20
180/180 [==============================] - 3s 14ms/step - loss: 0.2895 - accuracy: 0.8776 - val_loss: 0.0688 - val_accuracy: 0.9939
Epoch 2/20
180/180 [==============================] - 2s 13ms/step - loss: 0.0528 - accuracy: 0.9887 - val_loss: 0.0268 - val_accuracy: 0.9951
Epoch 3/20
180/180 [==============================] - 2s 13ms/step - loss: 0.0283 - accuracy: 0.9929 - val_loss: 0.0191 - val_accuracy: 0.9962
Epoch 4/20
180/180 [==============================] - 2s 13ms/step - loss: 0.0193 - accuracy: 0.9947 - val_loss: 0.0125 - val_accuracy: 0.9957
Epoch 5/20
180/180 [==============================] - 2s 14ms/step - loss: 0.0167 - accuracy: 0.9949 - val_loss: 0.0102 - val_accuracy: 0.9978
Epoch 6/20
180/180 [==============================] - 2s 14ms/step - loss: 0.0137 - accuracy: 0.9957 - val_loss: 0.0069 - val_accuracy: 0.9982
Epoch 7/20
180/180 [==============================] - 2s 14ms/step - loss: 0.0124 - accuracy: 0.9961 - val_loss: 0.0049 - val_accuracy: 0.9987
Epoch 8/20
180/180 [==============================] - 2s 14ms/step - loss: 0.0093 - accuracy: 0.9972 - val_loss: 0.0022 - val_accuracy: 1.0000
Epoch 9/20
180/180 [==============================] - 3s 14ms/step - loss: 0.0094 - accuracy: 0.9973 - val_loss: 0.0033 - val_accuracy: 0.9996
Epoch 10/20
180/180 [==============================] - 2s 14ms/step - loss: 0.0083 - accuracy: 0.9973 - val_loss: 0.0025 - val_accuracy: 0.9993
Epoch 11/20
180/180 [==============================] - 2s 13ms/step - loss: 0.0063 - accuracy: 0.9981 - val_loss: 0.0037 - val_accuracy: 0.9998
Epoch 12/20
180/180 [==============================] - 3s 15ms/step - loss: 0.0067 - accuracy: 0.9981 - val_loss: 0.0024 - val_accuracy: 0.9998
Epoch 13/20
180/180 [==============================] - 3s 15ms/step - loss: 0.0056 - accuracy: 0.9981 - val_loss: 0.0014 - val_accuracy: 0.9998
Epoch 14/20
180/180 [==============================] - 3s 15ms/step - loss: 0.0063 - accuracy: 0.9977 - val_loss: 0.0039 - val_accuracy: 0.9993
Epoch 15/20
180/180 [==============================] - 3s 15ms/step - loss: 0.0056 - accuracy: 0.9982 - val_loss: 9.2163e-04 - val_accuracy: 1.0000
Epoch 16/20
180/180 [==============================] - 3s 14ms/step - loss: 0.0047 - accuracy: 0.9983 - val_loss: 0.0015 - val_accuracy: 0.9996
Epoch 17/20
180/180 [==============================] - 3s 15ms/step - loss: 0.0064 - accuracy: 0.9980 - val_loss: 6.0123e-04 - val_accuracy: 1.0000
Epoch 18/20
180/180 [==============================] - 3s 15ms/step - loss: 0.0062 - accuracy: 0.9981 - val_loss: 0.0015 - val_accuracy: 0.9998
Epoch 19/20
180/180 [==============================] - 3s 17ms/step - loss: 0.0059 - accuracy: 0.9982 - val_loss: 0.0020 - val_accuracy: 0.9998
Epoch 20/20
180/180 [==============================] - 3s 16ms/step - loss: 0.0037 - accuracy: 0.9988 - val_loss: 0.0021 - val_accuracy: 0.9996
Visualize the training history.
plt.plot(history.history["accuracy"], label = "training")
plt.plot(history.history["val_accuracy"], label = "validation")
plt.gca().set(xlabel = "epoch", ylabel = "accuracy")
plt.legend()
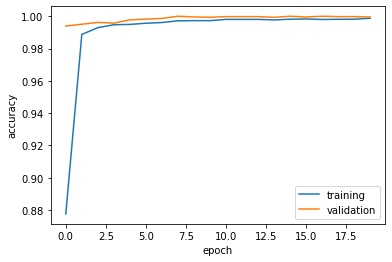
Compare to three model, we can they all hava a high accuracy. But model 3 has a higher accuracy than the other two models. Thus, using both the title and the text is better when deceting fake news.
4. Model Evaluation
Test the model performance on unseen test data. For this part, I will focus on model 3 because it has a best performance than the other two models.
test_url = "https://github.com/PhilChodrow/PIC16b/blob/master/datasets/fake_news_test.csv?raw=true"
test = pd.read_csv(test_url)
test_data = make_dataset(test)
model_1.evaluate(test_data)
model_2.evaluate(test_data)
model_3.evaluate(test_data)
225/225 [==============================] - 0s 1ms/step - loss: 0.0879 - accuracy: 0.9820
225/225 [==============================] - 2s 8ms/step - loss: 0.2890 - accuracy: 0.9396
225/225 [==============================] - 2s 8ms/step - loss: 0.0200 - accuracy: 0.9952
[0.019999492913484573, 0.9951890707015991]
Model 3 has a better performance. It has 99.52% accuracy.
5. Embedding Visualization
Using PCA to reduce the dimension down to a visualizable number.
2-dimensional embedding
weights = model_3.get_layer("embedding_1").get_weights()[0] # get the weights from the embedding layer
vocab = title_vectorize_layer.get_vocabulary() # get the vocabulary from our data prep for later
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
weights = pca.fit_transform(weights)
embedding_df = pd.DataFrame({
"word" : vocab,
"x" : weights[:,0],
"y" : weights[:,1]
})
embedding_df
| word | x | y | |
|---|---|---|---|
| 0 | -0.150144 | -0.003734 | |
| 1 | [UNK] | 0.278317 | 0.009919 |
| 2 | trump | -0.252798 | -0.040178 |
| 3 | to | 4.537495 | -0.088696 |
| 4 | video | 3.769611 | -0.065807 |
| ... | ... | ... | ... |
| 1995 | convicted | 0.548388 | -0.005080 |
| 1996 | constitution | 0.068745 | -0.058340 |
| 1997 | congo | -1.346927 | -0.094443 |
| 1998 | commander | -1.300501 | -0.097794 |
| 1999 | coast | -1.271358 | 0.032251 |
2000 rows x 3 columns
from plotly.io import write_html
import plotly.express as px
fig = px.scatter(embedding_df,
x="x",
y="y",
size=[2]*len(embedding_df),
hover_name = 'word'
)
fig.show()
write_html(fig, "b_1.html")
3-dimensional embedding
weights = model_3.get_layer("embedding_1").get_weights()[0] # get the weights from the embedding layer
vocab = title_vectorize_layer.get_vocabulary() # get the vocabulary from our data prep for later
pca = PCA(n_components=3)
weights = pca.fit_transform(weights)
embedding_df = pd.DataFrame({
"word" : vocab,
"x" : weights[:,0],
"y" : weights[:,1],
"z" : weights[:,2]
})
embedding_df
| word | x | y | z | |
|---|---|---|---|---|
| 0 | -0.150144 | -0.003721 | 0.001311 | |
| 1 | [UNK] | 0.278316 | 0.009919 | -0.000386 |
| 2 | trump | -0.252798 | -0.040178 | -0.063281 |
| 3 | to | 4.537493 | -0.088696 | -0.065394 |
| 4 | video | 3.769610 | -0.065807 | -0.052484 |
| ... | ... | ... | ... | ... |
| 1995 | convicted | 0.548387 | -0.005080 | -0.003860 |
| 1996 | constitution | 0.068745 | -0.058340 | -0.004885 |
| 1997 | congo | -1.346927 | -0.094443 | -0.072430 |
| 1998 | commander | -1.300501 | -0.097794 | 0.012638 |
| 1999 | coast | -1.271358 | 0.032252 | 0.004926 |
2000 rows x 4 columns
fig = px.scatter_3d(embedding_df,
x="x",
y="y",
z="z",
size=[2]*len(embedding_df),
hover_name = "word"
)
fig.show()
write_html(fig, "b_2.html")
In the embedding visualization,we can find most of words that are adjacent to each other have relation.
- In the 2-dimensional embedding visualization, word childrens is closer to word like school .
- In the 2-dimensional embedding visualization, word rubio is closer to word like candidate.
- In the 2-dimensional embedding visualization, word conference is closer to word like law.
- In the 3-dimensional embedding visualization, word lybia is closer to word like moscow.
- In the 3-dimensional embedding visualization, word supreme is closer to word like officer.