
Box Office Prediction
Team member: Tianliang Tao, Steve Zhu
Github Repo: https://github.com/TianliangTao/Project.git
Goal
In this project, our goal is that studios and investors can use forecasting methods to predict the revenue that a new movie can generate based on some given information, like budget, runtime, popularity, and so on.
In this project, the primary goal is to build a machine learning model to predict the revenue of movies according to the distributor, budget, release date, running time, genres and other information.
Required Tools
- Programming language: Python
- Compiler: Google Colab, Visual Studio Code
- Libraries involved: pandas, Numpy, Matplotlib, Sklearn, Plotly.express, Xgboost, Tensorflow, Scrapy
Flowchart
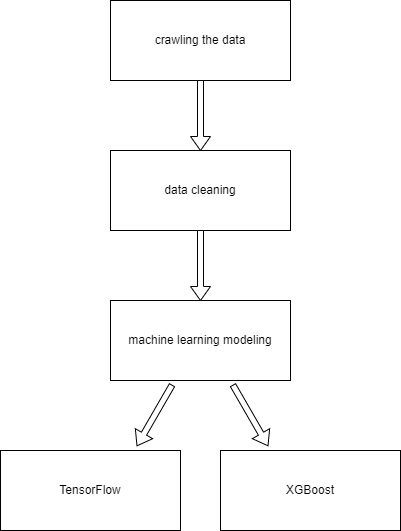
§1.Crawling the Data
In order to get the data, we use scrapy crawling the date from Box Office Mojo. We crawl the movie information from 1990 to 2021, which include the movie title, release date, runtime, budget, distibutor, gener, and so on.
import scrapy
class MovieSpider(scrapy.Spider):
name = "movie"
# urls to start scraping/crawling from
start_urls = [f"https://www.boxofficemojo.com/year/{1990 + i}" for i in range (33)]
def parse(self,response):
"""
This function is to access the website that include the list of movies for each year.
And choose 300 movies at most from each year.
Click the movie automatically and go to next page.
"""
for data in response.css("tr")[1:300]:
next_page = data.css("td.a-text-left.mojo-field-type-release.mojo-cell-wide a.a-link-normal").attrib["href"]
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback = self.parse_data_page)
def parse_data_page(self,response):
"""
This function is to crawl the information of each movie, which include the movie title,
domestic,international, worldwild,budget,MPAA, and so on.
"""
movie = response.css("div.a-fixed-left-grid-col.a-col-right h1.a-size-extra-large::text").get()
for grosses in response.css(".mojo-performance-summary-table"):
domestic = grosses.css("div:nth-child(2) > span:nth-child(3) > span:nth-child(1)::text").get()
international = grosses.css("div:nth-child(3) > span:nth-child(3) > a:nth-child(1) > span:nth-child(1)::text").get()
worldwild = grosses.css("div:nth-child(4) > span:nth-child(3) > a:nth-child(1) > span:nth-child(1)::text").get()
for data in response.css(".mojo-summary-values"):
distributor = data.css("div:nth-child(1) > span:nth-child(2)::text").get()
opening = data.css("div:nth-child(2) > span:nth-child(2) > span:nth-child(1)::text").get()
if data.css("div:nth-child(3) > span:nth-child(1)::text").get() == "Budget":
budget = data.css("div:nth-child(3) > span:nth-child(2) > span:nth-child(1)::text").get()
if data.css("div:nth-child(4) > span:nth-child(1)::text").get() == "Release Date":
release_date = data.css("div:nth-child(4) > span:nth-child(2) > a:nth-child(1)::text").get()
if data.css("div:nth-child(5) > span:nth-child(1)::text").get() == "MPAA":
MPAA = data.css("div:nth-child(5) > span:nth-child(2)::text").get()
if data.css("div:nth-child(6) > span:nth-child(1)::text").get() == "Running Time":
running_time = data.css("div:nth-child(6) > span:nth-child(2)::text").get()
if data.css("div:nth-child(7) > span:nth-child(1)::text").get() == "Genres":
genres = data.css("div.a-section:nth-child(7) > span:nth-child(2)::text").get()
yield{
"Movies":movie,
"Domestic":domestic,
"International":international,
"Worldwild":worldwild,
"Distributor":distributor,
"Opening":opening,
"Budget":budget,
"Release_Date":release_date,
"MPAA":MPAA,
"Runing_Time":running_time,
"Genres":genres
}
We have a 503 in the process of scraping the data because too much data need to crawl. In order to solve this error, we create download middleware that keeps retrying with new proxy the URLs that have 503 response until they are successfully scraped.
# Retry many times since proxies often fail
RETRY_TIMES = 10
# Retry on most error codes since proxies fail for different reasons
RETRY_HTTP_CODES = [500, 503, 504, 400, 403, 404, 408]
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 1,
'scrapy_proxies.RandomProxy': 400,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 110,
}
PROXY_LIST = "/Users/10647/anaconda3/envs/movie/proxylist.txt"
# Proxy mode
# 0 = Every requests have different proxy
# 1 = Take only one proxy from the list and assign it to every requests
# 2 = Put a custom proxy to use in the settings
PROXY_MODE = 0
§2.Data Cleaning and Split
In this step, we need to check the data and clean the data.
#load the data and take a look
url = "https://github.com/TianliangTao/Project/blob/main/movie/movie.csv?raw=true"
df = pd.read_csv(url)
df.head()

We see there are some non sense symbols, so we need to
- Delete the dollar sign and comma
- Check whether the distributor name is unique
- Check how many ‘nan’ we have in our data
- Change the release date to number
- Change the running time to minutes only
- Convert genre features to list
We will use modules to break down large programs into small manageable and organized files. Modules will save the code with the file extension .py. We create different modules for data cleaning, split dataser into training data and test data, and keras. Model. In order to access modules on colab, I mount Google Drive using an authorization code.
from google.colab import drive
import sys
drive.mount('/content/gdrive')
sys.path.append('/content/gdrive/MyDrive/box office/modules')
This part is a module for data cleaning. We will use import data_clean import this module in our main code page. Due to Distributor, MPAA, Release_Year, Release_Month and Genres features contain various type of values, we covert them to dummy variables. In order to make our model converge to better weights, we use data normalization to norem the data.
import pandas as pd
import numpy as np
from sklearn import preprocessing
def clean_number(data):
"""
Input data contains dollar sign and comma in str format
Ouput the data in int format without nan, the dollar sign and comma
"""
df = data.copy()
# Remove comma
df = df.str.replace(',', '',regex=True)
# Remove dollar sign
df = df.str.replace('$', '',regex=True)
# Convert to int type
df = df.astype(int)
return df
def change_runningtime(data):
"""
Input data contains running time information in str format
Output the running time in minitues and in int format
"""
df = data.copy()
# Add '00 min' to the data so the index will not be out of range for the data does not contain miniutes inforamtion
df = df + ' 00 min'
df = df.str.split(' ').apply(lambda x: int(x[0]) * 60 + int(x[2]))
return df
def prepare_data(data):
"""
This function will call the function clean_number() and the function change_runningtime().
clean the data, conver certain data to dummy variables and normalize the data
"""
# Take a copy first
df = data.copy()
# Fix typo
df = df.rename(columns = {'Worldwild':'Worldwide', 'Runing_Time':'Running_Time'})
# Put 0 in the international feature of movies do not have the international box office information
df['International'] = df['International'].replace(np.nan, '0')
# Delete the movies with missing information
df = df.dropna()
# Delete the dollar sign and the comma, and convert the number in to int format
df['Domestic'] = clean_number(df['Domestic'])
df['International'] = clean_number(df['International'])
df['Worldwide'] = clean_number(df['Worldwide'])
df['Opening'] = clean_number(df['Opening'])
df['Budget'] = clean_number(df['Budget'])
# Convert the format of running_time to minutes
df['Running_Time'] = change_runningtime(df['Running_Time'])
# Extract the year and month information from release_date
df['Release_Date'] = pd.to_datetime(df['Release_Date'])
df['Release_Year'] = df['Release_Date'].dt.year
df['Release_Month'] = df['Release_Date'].dt.month
# Clean the space and \n in Genres feature and create lists contain genre information
df['Genres'] = df['Genres'].str.replace(' ','')
df['Genres'] = df['Genres'].str.split('\n\n')
# Covert Distributor, MPAA, Release_Year, Release_Month and Genres features to dummy variables
dist_dum = pd.get_dummies(df.Distributor, prefix='Distributor')
mpaa_dum = pd.get_dummies(df.MPAA, prefix="MPAA")
year_dum = pd.get_dummies(df.Release_Year, prefix="Release_Year")
month_dum = pd.get_dummies(df.Release_Month, prefix="Release_Month")
genre_dum = pd.get_dummies(df['Genres'].apply(pd.Series).stack(), prefix="Genre").groupby(level=0).sum()
df = pd.concat([df, dist_dum, mpaa_dum, year_dum, month_dum, genre_dum], axis=1)
df.drop(columns=['Movies', 'Distributor', 'MPAA', 'Release_Date', 'Release_Year', 'Release_Month', 'Genres'], inplace=True)
# Normalize the data
columns_to_normalize = ['Domestic', 'International', 'Worldwide', 'Opening', 'Budget', 'Running_Time']
mean_scaler = preprocessing.StandardScaler()
df[columns_to_normalize] = mean_scaler.fit_transform(df[columns_to_normalize])
df['Worldwide'] = df['Worldwide'].to_numpy(dtype = np.float32).reshape((-1, 1))
return df
To check the data after cleaning.
import data_clean1
df1 = data_clean1.prepare_data(df)
df1.head()

In order to predict the box office revenue, we split data in to three group. 70% data for trainng. 10% data for validation, and 20% for testing. And we also create a module for this part.
import tensorflow as tf
def make_dataset(data, shuffle=True):
"""
shuffles the elements of this dataset
Create the train, test and validation data set
"""
df = data.copy()
labels = df['Worldwide']
features = df.drop(columns = ['Worldwide'])
# get the slices of array in the form of objects
ds = tf.data.Dataset.from_tensor_slices((features, labels))
# shuffles the elements of dataset
if shuffle:
ds = ds.shuffle(buffer_size=len(ds))
train_size = int(0.7*len(ds))
val_size = int(0.1*len(ds))
# data[:train_size]
train = ds.take(train_size).batch(20)
# data[train_size : train_size + val_size]
val = ds.skip(train_size).take(val_size).batch(20)
# data[train_size + val_size:]
test = ds.skip(train_size+val_size).batch(20)
return train,val,test
§3.Modeling
(a) TensorFlow
Create a machine learning model using tensorflow. We also creat a module for this create_modle() function. This module will assemble layers into the model, and compile the model, with loss and optimizer functions.
import tensorflow as tf
from keras import regularizers
from keras import optimizers
def create_model(input_size):
"""
Creat a sequence of layers. The first layer is input layer and the final layer is an output layer
"""
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(input_size, )),
tf.keras.layers.Dense(356,activation='relu',kernel_regularizer=regularizers.l1(.001)),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(256,kernel_regularizer=regularizers.l1(.001),activation='relu'),
tf.keras.layers.Dense(units = 1)
])
# use model.compile() config the model with optimizer,losses and metrics
model.compile(optimizer=tf.keras.optimizers.RMSprop(learning_rate=.001),loss='mse', metrics=['mean_squared_logarithmic_error'])
return model
Train the model by calling the fit method.
import model
model1 = model.create_model(160)
history = model1.fit(train, validation_data = val, epochs = 100)

Plot the origin revenue and revenue of prediction.
test_predictions = model1.predict(test).flatten()
test_true = np.concatenate([y for x, y in test], axis=0)
fig = px.scatter(x = test_true, y = test_predictions)
fig.update_layout(
width = 1000,
height = 1000,
yaxis_range=[-1,7],
xaxis_range=[-1,7]
)
fig.update_yaxes(
scaleanchor = "x",
scaleratio = 1,
)
fig.show()
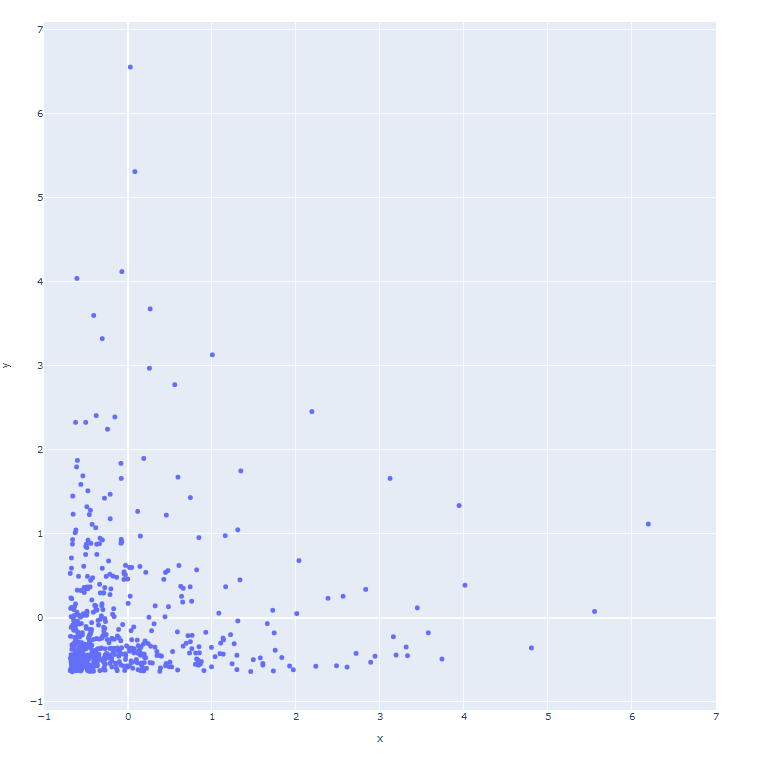
We see that our model performance is not good. We need to add more features into our data to improve the performance. We use TMDB API add original_language and popularity into the dataset.
# create an empty dataset
added_df = pd.DataFrame(columns=[])
# use tmdb api search the original_language and popularity of each movie in the previous dataset
for movie_name in df['Movies']:
response = requests.get('https://api.themoviedb.org/3/search/movie?api_key=c856b5dd6e0385ee3a021059a0a6cca1&query='+movie_name)
responded = response.json()
try:
added_info = pd.DataFrame({'Original_Language': [responded['results'][0]['original_language']], 'Popularity': [responded['results'][0]['popularity']]})
except:
added_info = pd.DataFrame(np.nan, index = [0], columns=['Original_Language', 'Popularity'])
# append the data
added_df = added_df.append(added_info)
added_df = added_df.reset_index()
added_df
Add the new data into previous dataset.
df['Original_Language'] = added_df['Original_Language']
df['Popularity'] = added_df['Popularity']
We train this new dataset and model it, but it also have a poor performence. We find add more features into our data cannot improve the performance. Thus we decided to use a new model to train the data.
(b)XGBoost
We will use XGBoost to train a model to find patterns in a dataset with other features and then uses the trained model to predict box office revenue.
from xgboost import XGBRegressor,plot_importance
train, test = train_test_split(df4, test_size = 0.2, random_state = 1)
y_train = train['Worldwide']
y_test = test['Worldwide']
x_train = train.drop(columns=['Worldwide'])
x_test = test.drop(columns=['Worldwide'])
xgb_model = XGBRegressor(learning_rate=0.05,
n_estimators=10000,max_depth=4)
xgb_model.fit(x_train, y_train, early_stopping_rounds=100,
eval_set=[(x_test, y_test)], eval_metric = 'rmse')
xbg_val_predictions=xgb_model.predict(x_test)
test_predictions = xgb_model.predict(x_test)
test_true = y_test
fig = px.scatter(x = test_true, y = test_predictions)
fig.update_layout(
width = 1000,
height = 1000,
yaxis_range=[0,2000000000],
xaxis_range=[0,2000000000]
)
fig.update_yaxes(
scaleanchor = "x",
scaleratio = 1,
)
fig.show()
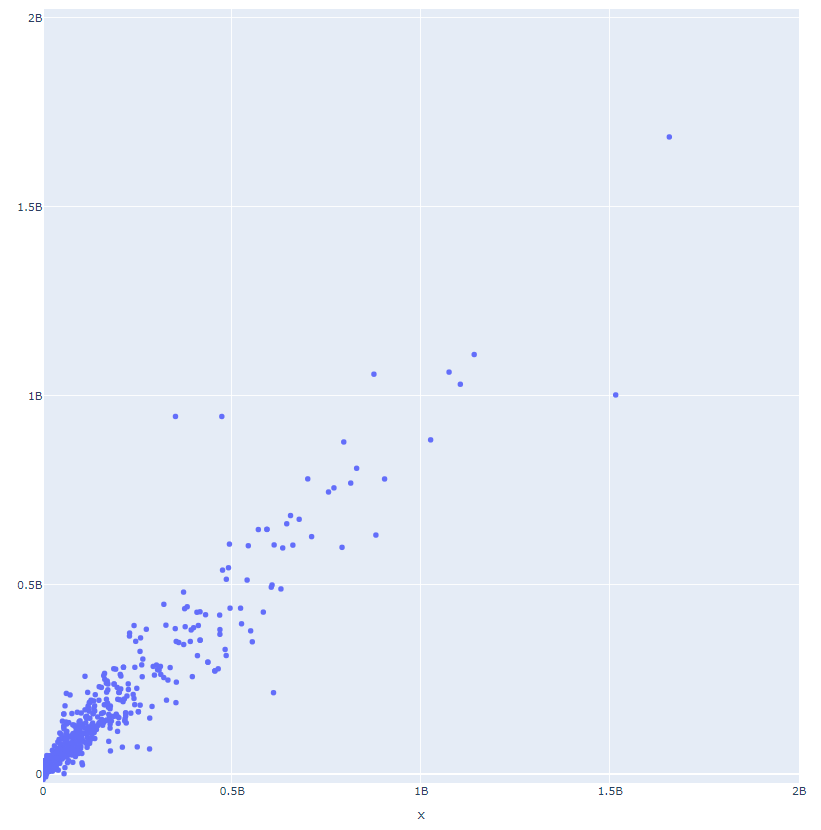
According to the plot we cansee that our model has a good performence. XGBoost has a higher result in terms of accuracy and it fits this model better.
Conclusion
We can predict box office revenue by using feature such as budget, popularity, runtime, etc. People in the film industry and film related can use machine learning model to predictbox office revenue by inputting the features. According to prediction result, our model has some limitations because it cannot provide accurate results. In order to improve the model performance, we need to add more data sets and add some more features. Therefor, we need more observation data to capturemore variability in our testing data set. A large number of data sets can better measure the accuracy of the model. And different machine learning frameworks can affect the accuracy of the result.